Stéphane d'Ascoli
Stéphane d'Ascoli
Bio
Research
Outreach
Music
Travel
CV
Light
Dark
Automatic
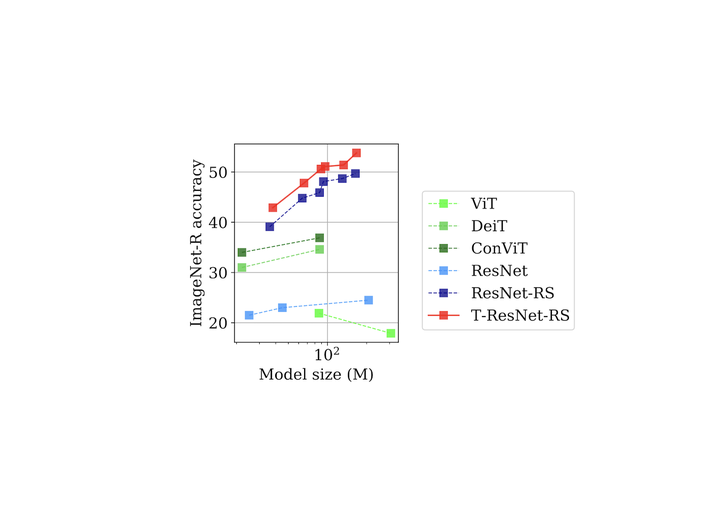
Transformed CNNs: recasting pre-trained convolutional layers with self-attention
Stéphane d'Ascoli
,
Levent Sagun
,
Giulio Biroli
,
Ari Morcos
January 2021
Cite
ArXiv
Type
Journal article
Publication
arXiv preprint arXiv:2106.05795
Related
On the interplay between data structure and loss function in classification problems
ConViT: Improving Vision Transformers with Soft Convolutional Inductive Biases
Triple descent and the two kinds of overfitting: where and why do they appear?
Finding the Needle in the Haystack with Convolutions: on the benefits of architectural bias
Jamming transition as a paradigm to understand the loss landscape of deep neural networks
Cite
×